what is redis?
레디스란?
Redis(Remote Dictionary Server)는 오픈 소스 인메모리 키-값 데이터 저장소로 주로 인메모리 데이터베이스, 캐시, 메시지 브로커, 큐로 사용됩니다. 오늘날 대부분의 최신 애플리케이션은 Redis를 캐시 서버로 사용합니다.
캐싱이 필요한 이유는 무엇입니까?
캐싱은 불필요한 네트워크 호출, 데이터베이스 호출 및 하드 디스크에 대한 반복적인 읽기-쓰기 작업을 방지하여 응용 프로그램 성능을 향상시키는 데 주로 사용됩니다.
예를 들어 애플리케이션이 국가 마스터, 언어 마스터, 애플리케이션 구성 등과 같은 일부 정적 데이터를 자주 사용하고 일부 파일이나 내부적으로 하드 디스크를 사용하는 데이터베이스에 저장되어 있다고 가정해 보겠습니다.
그래서 이들은 가장 자주 사용되는 데이터이므로 응용 프로그램이 필요할 때마다 내부적으로 하나의 요청이 데이터베이스 또는 파일로 이동하여 밑줄이 있는 하드 디스크로 입출력 작업을 증가시키고 성능 문제를 일으킵니다.
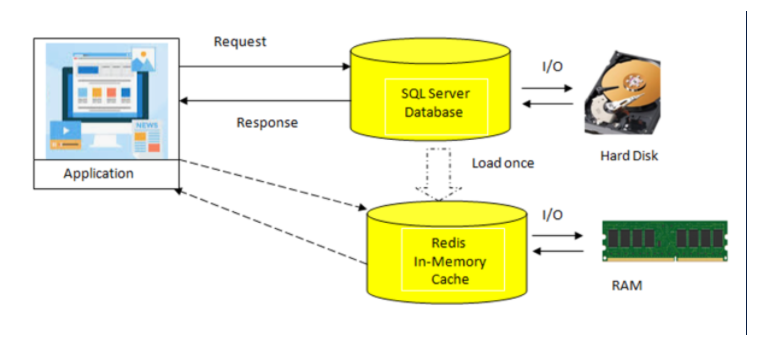
이제 성능을 향상시키기 위해 자주 사용하는 정적 데이터를 하드 디스크에서 인메모리(예: RAM)로 한 번 로드한 다음 후속 요청에 대해 디스크가 아닌 RAM에서 제공할 수 있습니다.
Redis의 인기 있는 사용 사례
- 데이터 캐싱
- 세션 저장소
- Pub/Sub 메시징 시스템
Who uses Redis?

왜 Collection이 중요한가요?
레디스는 In-Memory 데이터베이스입니다. 즉, 모든 데이터를 메모리에 저장하고 조회합니다. 기존 관계형 데이터베이스(Oracle, MySQL) 보다 훨씬 빠른데 그 이유는 메모리 접근이 디스크 접근보다 빠르기 때문입니다. 하지만 빠르다는 것은 레디스의 여러 특징 중 일부분입니다. 다른 In-Memory 데이터베이스(ex. Memcached) 와의 가장 큰 차이점은 다양한 자료구조 를 지원한다는 것입니다. 레디스는 아래처럼 다양한 자료구조를 Key-Value 형태로 저장합니다.

레디스는 기본적으로 String, Bitmap, Hash, List, Set, Sorted Set 를 제공했고, 버전이 올라가면서 현재는 Geospatial Index, Hyperloglog, Stream 등의 자료형도 지원하고 있습니다.
그렇다면 이렇게 다양한 자료구조를 제공하는게 왜 중요할까요?
바로 개발의 편의성과 난이도 때문입니다.
예를 들어 실시간 랭킹 서버를 구현할 때 관계형 DBMS를 이용한다면 DB에 데이터를 저장하고, 저장된 SCORE 값으로 정렬하여 다시 읽어오는 과정이 필요할 것입니다. 개수가 많아지면 속도가 느려질 텐데요, 이 과정에서 디스크를 사용하기 때문입니다. In-memory 기반으로 서버에서 데이터를 처리하도록 직접 코드를 짤 수도 있겠지만.. 레디스의 Sorted-Set을 이용하는게 더 빠르고 간단한 방법일 것입니다.

레디스는 트랜잭션의 문제도 해결해 줄 수 있습니다. 싱글 스레드로 동작하는 서버의 모든 자료구조는 atomic 하기 때문에, race condition을 피해 데이터의 정합성을 보장하기 쉽습니다.
즉, 외부의 Collections을 잘 이용하는 것만으로 개발 시간 단축이 가능하고, 생각하지 못한 여러가지 문제를 줄여줄 수 있으므로 개발자는 비즈니스 로직에 집중할 수 있다는 큰 장점이 존재합니다.
reference:
https://meetup.toast.com/posts/224
https://www.steps2code.com/post/how-to-improve-api-performance-by-using-redis-cache