DevOps
Deploying to Amazon Elastic Container Service
길순이
2022. 3. 31. 22:28
현 상황의 배포 시스템을 컨테이너 기반 배포시스템으로 빠르게 구축합니다. 추후 필요에 따라 k8s 기반으로 넘어갈 것이지만 현재 당면한 배포시스템의 문제로 인해 일단 빠르게 시스템을 구축하는 것을 목표로 합니다.
개요:
오늘 오전 10:50 부터 약 3~40분 동안 강대 서비스 장애가 있었습니다. 장애 진행 상황, 원인 및 대응책을 말씀드리려고 합니다.원인 및 대응책 요약:
장애 원인은 요약하면 낙후된 배포 시스템과, 실수, 빠른 롤백이 불가한 배포 환경이라고 볼 수 있습니다. 다양한 프로젝트와 이슈 대응으로 배포 시스템 개선이 아직 이루어지지 못했는데 이번 스프린트에서 개발팀은 무조건 최신 기술을 활용한 배포 시스템을 도입하려고 합니다.timeline:
- 10:40 경 강대 백엔드-1 서버 배포 완료: 문제가 있었지만 배포 시스템에 오류 표시 안됨
- 10:50 경 강대 백엔드-2 서버 배포 완료. 오류 메시지 없이 전체 서비스 장애 시작
- 11:00 원인 파악. 12/8 릴리즈를 위해 신규로 추가된 데이터베이스 테이블의 권한 설정에 문제가 있었음
- 11:30 경 수정 백엔드 배포 및 이슈 해결
장애 원인:
- 우선적으로는 데이터베이스 테이블 권한 설정에 대한 실수
- 그럼에도 불구하고 동시 다발적으로 진행되는 많은 이슈로 인한 실수 가능성이 높은 상황인 것은 해결책을 생각할 때 고려 해야 함
- 배포 시스템에서 심각한 배포 문제에 대한 오류 메시지가 표시 되지 않는 것도 배포 중 사고 위험을 높이는 이유
action items:
- 빠르고 안전한 롤백을 가능하게하는 배포 시스템이 절실함. Docker를 사용하는 이미지 기반 배포 시스템이 있었으면 장애 시간을 10분 미만으로 할 수 있었음
- 프로덕션 배포를 하기 전에 stage 단계를 만들어서 백엔드 서버에 문제가 없는지 확인할 수 있는 배포 시스템 기능이 필요함
- 배포 중 서버 로그 및 메트릭을 손쉽게 확인할 수 있는 모니터링 시스템 추가 필요
- 메트릭은 좋은 상용 솔루션을 활용할 수 있음
- 서버 로그는 내부 tool을 개선하여 개발자가 쉽게 배포 서버 로그를 확인할 수 있게 개선할 필요 있음
- 실수를 줄이기 위해 사전 리뷰 및 테스트에 좀더 개발 시간을 사용할 필요가 있음
- 그럼에도 불구하고 실수는 언제나 발생할 수 있기 때문에 그것을 확인 및 방지할 수 있는 다중의 안전책을 마련 해야함배포 시스템도 다양한 옵션이 있으나 가장 빠른 시간 안에 도입하여 배포 관련 안정성을 크게 높일 수 있는 방향으로 신속히 대응하도록 하겠습니다.
감사합니다.
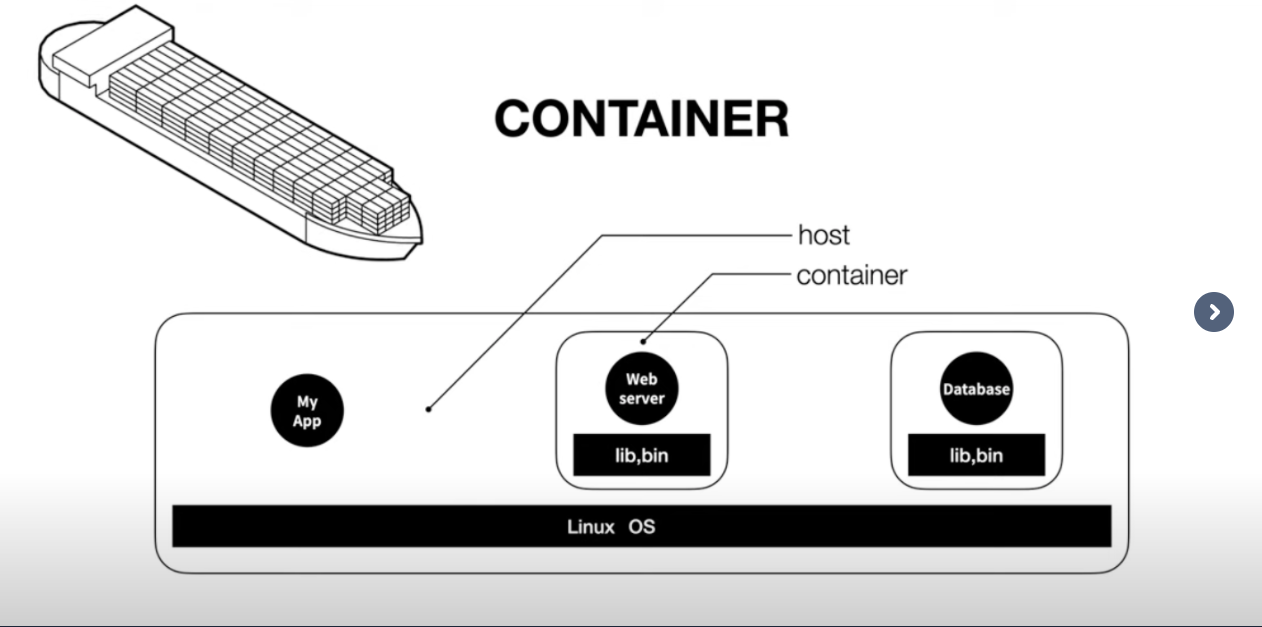
하나의 os에서 격리된 컨테이너 실행 환경을 제공합니다.
매번 실행환경을 셋팅 할 필요도 없다.
간편하게 이미지라는 작업으로 가능하게 됩니다.
ECS의 클러스터는 도커 컨테이너를 실행할 수 있는 논리적인 공간이라고 볼 수 있는데요, 우리가 사용하는 도커 컨테이너는 도커가 설치된 컨테이너 인스턴스에서 컨테이너가 실행되며 이 인스턴스들을 목적에 따라 하나로 묶어주는 것이 바로 클러스터라고 할 수 있습니다.
- 구현 된 아키텍처
